
A beginner's guide to your first GraphQL queries


GraphQL is a query language and server-side runtime for APIs that are used to retrieve specific data requirements in a query. It was developed as a more efficient and flexible alternative to REST for fetching data for applications. The clients can request the specific data they want and get that particular data with a single query, which prevents over-fetching problems. This article will lead you through your first GraphQL queries, so you can learn how to optimize your website’s performance.
GraphQL enables declarative data fetching by providing a single endpoint that handles all data requests with just one API call. This single request prevents the need for back-and-forth requests to the server. Compare it to REST API, which has multiple endpoints for different requests and leads to several data fetches.
Certain key concepts in GraphQL include:
-
Schemas: A GraphQL schema serves as a guide that defines the structures, types, and operations of data that can be queried in GraphQL API. SDL (Schema Definition Language) is used to define schemas.
-
Types: The type system lets you define the custom data type you need to fetch data. There are object types (e.g., Characters or Users) and built-in scalar types (e.g., Int or String), etc.,
-
Queries: They specify the data fields to be retrieved from the GraphQL server.
Now that you know what GraphQL is, let’s begin writing some queries.
The GraphQL Query Structure
A query is a GraphQL request for data from a database. With the query, a client can specify the data it wants and the format it wants returned.
We will use the AniList API as our data source for the examples and demonstration on how to fetch data from a database.
The query typically starts with the “query” keyword, which refers to the operation type, followed by the root field or “operation name,” which is a descriptive name of the operation. Think of operation names as function names. After that comes the set of fields you want to retrieve from the server.
query {
Page {
media {
id
title {
english
}
}
}
}Here, we use the Page query to receive the complete array of media objects. The fields we’re trying to query for on the Media are the id and title. The API will respond with the id and title of the available Media items.
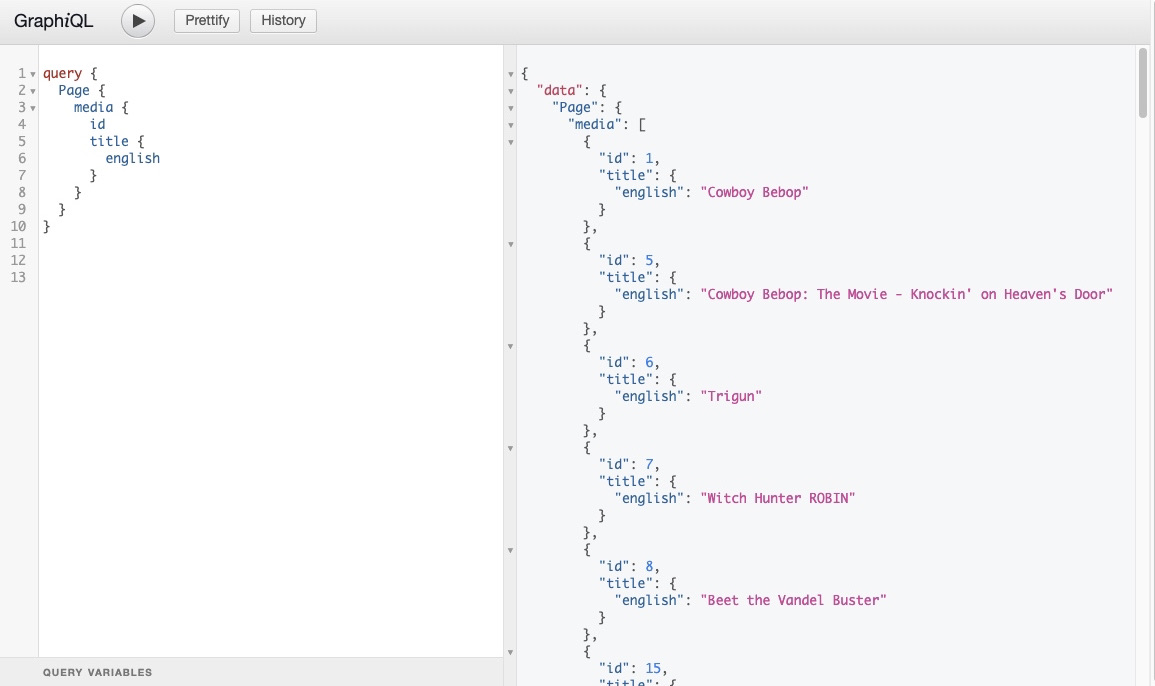 Once the query gets to the GraphQL service, a resolver will execute it, and the server will respond with the data in the format the query was sent.
Once the query gets to the GraphQL service, a resolver will execute it, and the server will respond with the data in the format the query was sent.
The query is also structured to allow the client to specify sub-fields on objects and their fields. This capability of GraphQL queries enables traversing the relationships between fields and retrieving nested data.
Let’s demonstrate this below.
query {
Character (sort: FAVOURITES) {
name {
first
last
native
}
dateOfBirth {
year
month
day
}
gender
age
}
}The query specifies that it wants to retrieve the first, last, and native names of a favorite Character from the Anilist Anime API. It also requests the nested fields of year, month, and day of the Chracter’s dateOfBirth.
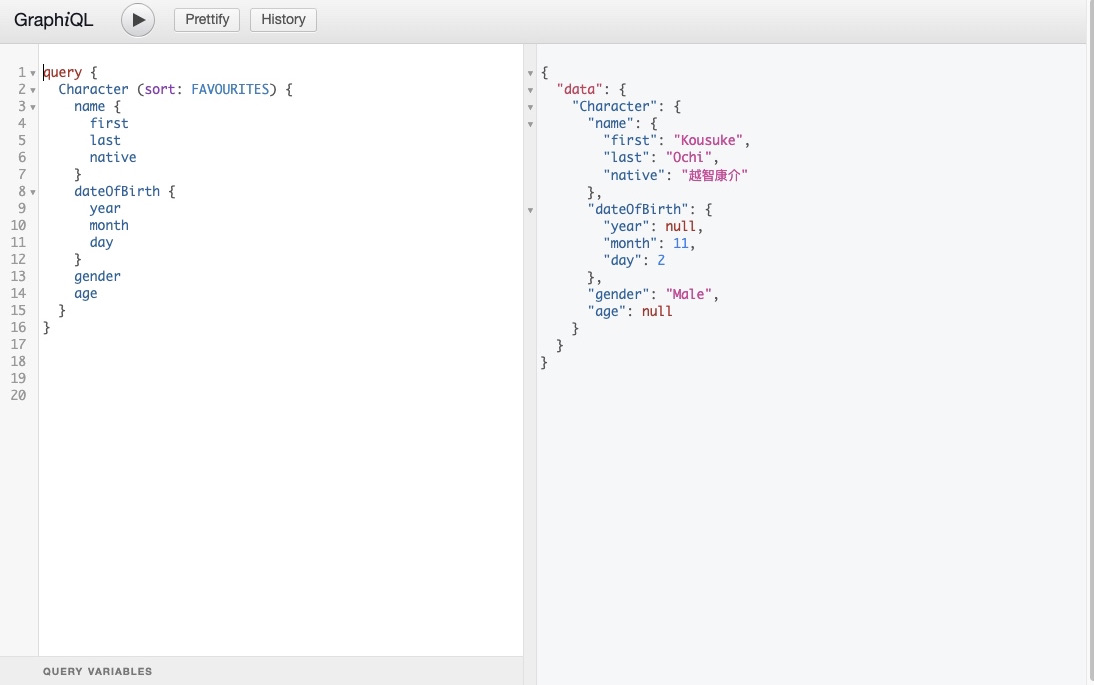
Thus, GraphQL reduces the number of requests clients make to the server through its nested fields characteristic.
Arguments
What if you want to request a specific detail on the Media or a Character? That’s where arguments come in. The query lets you pass in arguments in a field to get specific info.
query {
Media(id: 8) {
id
title {
english
}
}
}We didn’t pass in an argument in the first code example, so the server responded with a long list of all the Media id and title. Here, we’re asking for the Media with an id of 8 specifically, which we get.
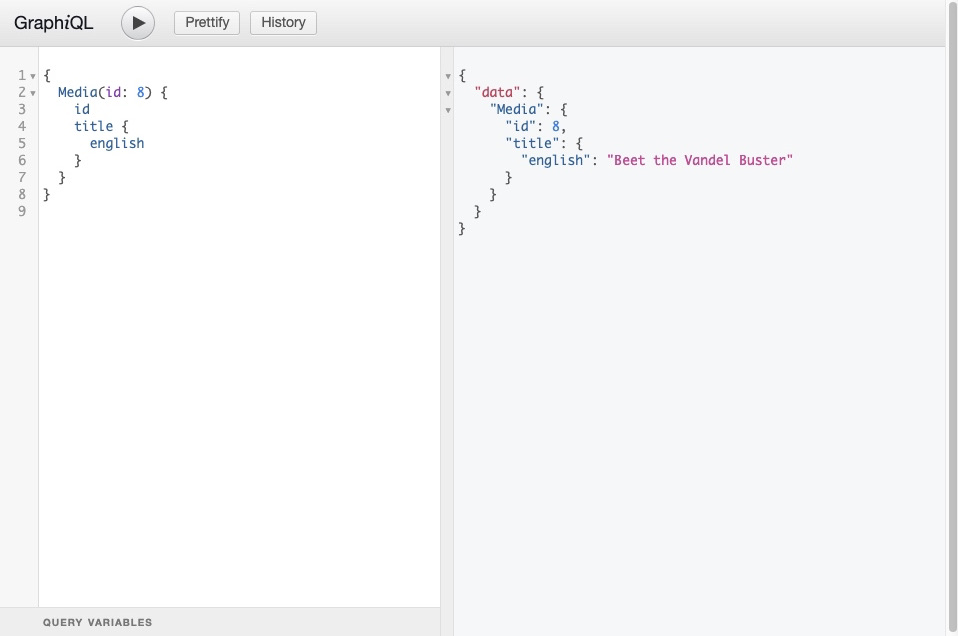
You can also include arguments on nested fields if the API provides specialized data. This makes GraphQL a better alternative to REST by preventing over-fetching.
Here’s an example
query {
Media(id: 1) {
title {
romaji
english
}
episodes
averageScore
recommendations(perPage: 5, sort: ID_DESC) {
nodes {
userRating
mediaRecommendation {
title {
romaji
}
averageScore
}
}
}
}
}Here, we are querying for the Media with the ID of “1”. The query includes several nested fields, and we pass in arguments to get specific data for some of these fields.
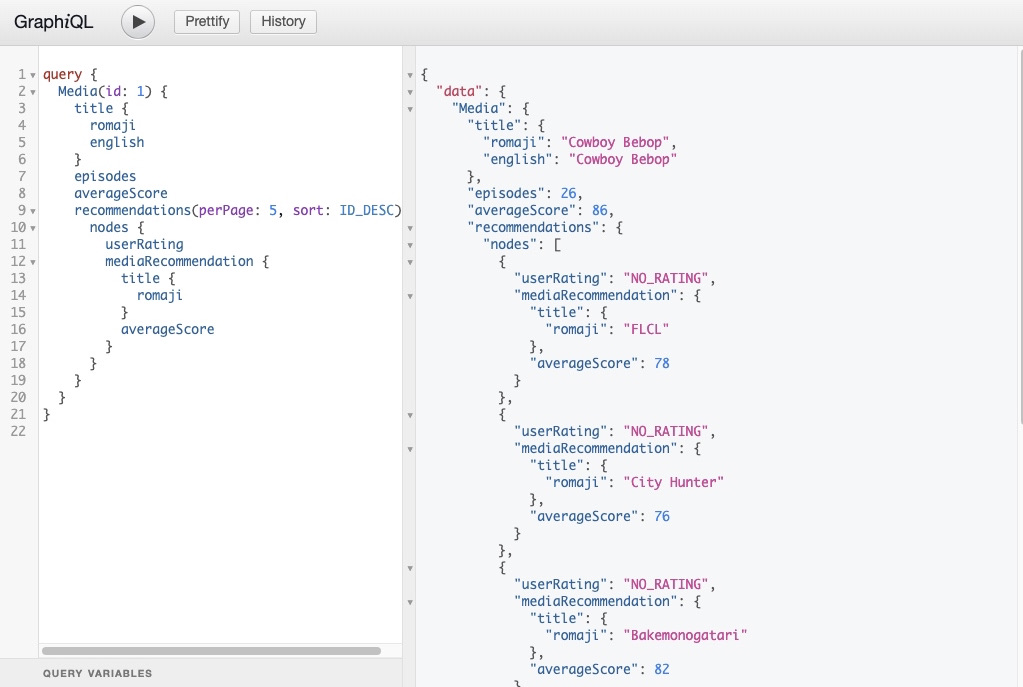
We query for the recommendations field, which is a subfield of the Media field and we include the arguments perPage: 5 to limit the number of recommendations returned to 5 and sort: ID_DESC to sort the recommendations by ID in descending order.
We also access the nodes field under the recommendations field, representing individual recommendation items. We retrieve the userRating and mediaRecommendation for each recommendation. Nested in the mediaRecommendation, we retrieve the romaji title and the averageScore of the recommended Media.
Writing your First Query and Fetching with GraphQL
We are going to do two things in this section:
i. Define a query operation
ii. Execute the query by sending it to the GraphQL server using an HTTP request
As we already demonstrated, you start by defining the “query” keyword. You can perform other operations with GraphQL, such as mutation to modify data and subscription to receive real-time updates.
We will query the id, title, and description of the Media with the id of 5.
query {
Media(id: 5) {
id
title {
romaji
english
}
description
}
}In the snippet, we pass the id of 5 as an argument to the Media. We also sub-specify the languages we want to get the titles in.
To demonstrate how to execute the query and fetch data from the server, the Fetch API in JavaScript will send an HTTP request.
<!DOCTYPE html>
<html>
<body>
<div id="result"></div>
<script>
const query = `
query {
Media(id: 5) {
id
title {
romaji
english
}
description
}
}
`;
fetch('https://graphql.anilist.co', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ query }),
})
.then(response => response.json())
.then(data => {
const resultElement = document.getElementById('result');
resultElement.textContent = JSON.stringify(data, null, 2);
})
.catch(error => {
console.error(error);
});
</script>
</body>
</html>First, we passed in the query we wrote to the query variable. Then we specify the URL of the AniList API as the single endpoint for the request in the fetch function. The response from the server is parsed as JSON, and the result is displayed in the specified HTML element.

The response is in JSON format corresponding to the requested data’s structure. It is retrieved in a nested structure where the data field contains an object with the Media field. The Media field, in turn, has the nested fields of id, title, and description. This structure follows the data hierarchy.
There are more advanced concepts we’ll briefly consider.
Session Replay for Developers
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — an open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
Advanced GraphQL Query Techniques
Let’s explore some advanced techniques in GraphQL that allow for more precise and efficient querying.
Aliases
Aliases are necessary when you need to specify different names for the same field you are trying to query. It is particularly useful when you need to retrieve multiple sets of data in one request.
query {
Media(id: 1) {
id
romajiTitle: title {
romaji
}
englishTitle: title {
english
}
}
In this example, we specified different names in the title field using the romajiTitle and englishTitle aliases, telling the server that we want to retrieve the titles separately.
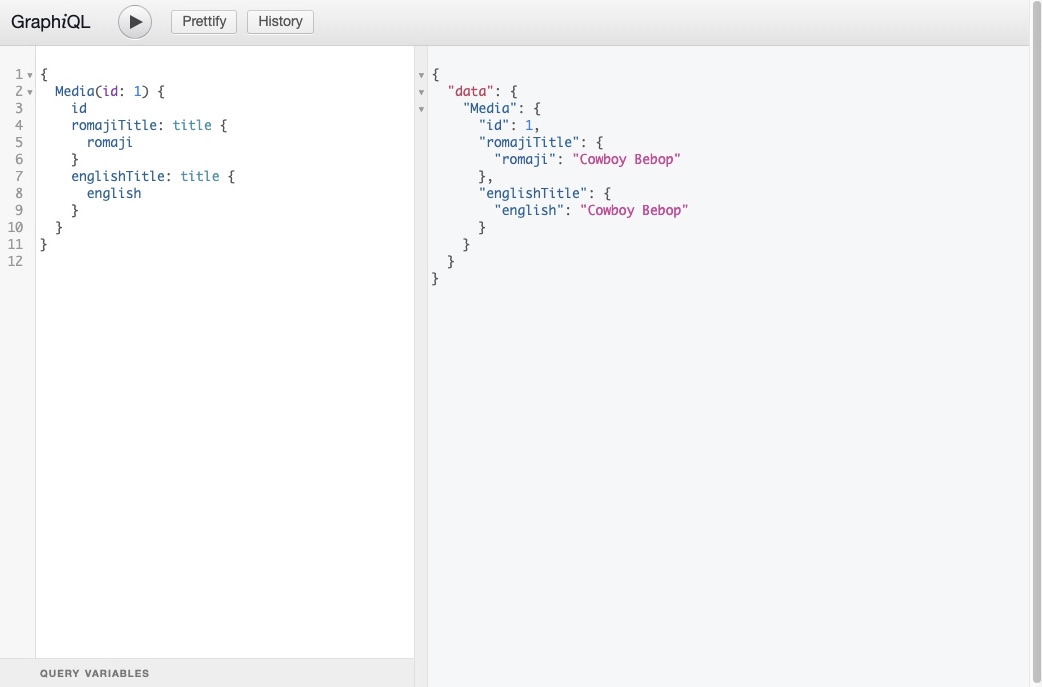
Using aliases (romajiTitle and englishTitle), different names are assigned to the fields to differentiate them in the response.
You will find aliases relevant when avoiding naming conflicts for larger schemas.
Fragments
A fragment is part of a query syntax reusable in multiple other queries. Fragments help to keep your queries organized by avoiding repetitive fields.
query {
Media(id: 1) {
...mediaFragment
}
}
fragment mediaFragment on Media {
id
title {
romaji
english
}
description
}In this example, we called the fragment keyword on the fragment named mediaFragment and specified the fields we wanted to get. Then we reference the fragment by its name in the main query preceded by .... If we have to get these same fields on a Media with another id, we only have to reference the fragment.
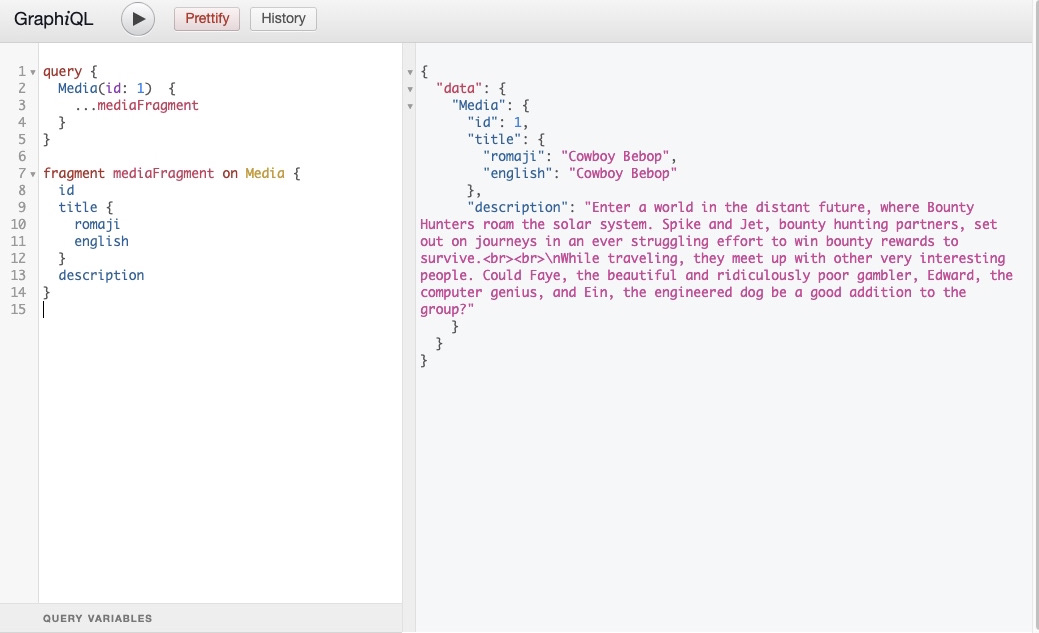
Fragments help reuse the same field in multiple queries.
Conclusion
This article explains what GraphQL is and how it is more efficient than REST API. It also demonstrated the GraphQL structure and how to fetch data with GraphQL. Finally, it went through Advanced GraphQL techniques.
You can visit the Anilist API documentation to further explore GraphQL and write queries.
I hope you have found this useful and can now go on to writing more queries.
Gain Debugging Superpowers
Unleash the power of session replay to reproduce bugs and track user frustrations. Get complete visibility into your frontend with OpenReplay, the most advanced open-source session replay tool for developers.


