
Optimizing JavaScript... Which Way?


Optimizing JavaScript performance is not a trivial task, and this article will show you how to tackle one problem involving large arrays and many operations, going from a first (slow) version to a (much optimized) final one, discussing many good and bad options along the way.

Discover how at OpenReplay.com.
In our previous articles we saw two distinct ways to optimize long array operations… but which is better? Without paying attention to actual performance, we could note that the first (very functional!) solution, using transducers, could be considered complex and somewhat challenging to understand. On the other hand, the more straightforward solution, without transducers, was longer but arguably clearer. In any case, that’s not what worries us; after all, usage was similar for both solutions, so their internal complexity isn’t significant. We need to compare both solutions in terms of performance and maybe try to optimize them to the maximum so we can decide which way to go. In this article, we’ll do precisely that:
- We’ll first plan how to go about testing.
- We’ll then do some trial runs.
- We’ll finish by applying several possible JavaScript optimization techniques and measuring their results.
- By the end of the article, we’ll have a good idea about which of the two solutions is best regarding overall speed. But first, let’s remember the problem and its solutions.
The problem and how we solved it
Imagine we have a (large) array and want to perform several mapping and filtering operations (plus a possible final reducing one) to it. Using the .map() and .filter() methods would lead to a solution that needs creating and later discarding many intermediate arrays, as shown at left in the image below.
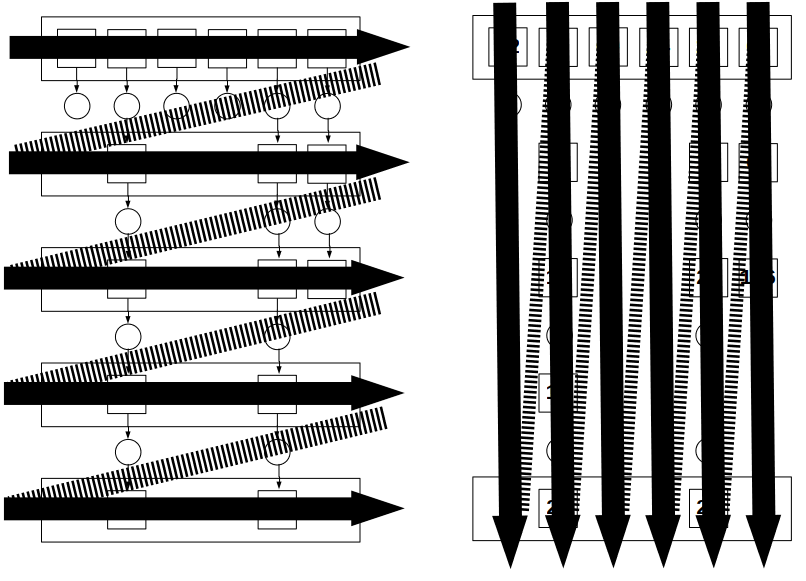 The better idea is to go value by value instead of going transformation by transformation, as shown at the right in the image above. That way, we perform the same number of operations, but we don’t need any intermediate arrays and save time; nice!
The transducer solution produced a
The better idea is to go value by value instead of going transformation by transformation, as shown at the right in the image above. That way, we perform the same number of operations, but we don’t need any intermediate arrays and save time; nice!
The transducer solution produced a transduce2() function that transformed the whole set of operations into a single reduce() call; check the previous article for details and explanations.
const transduce2 = (arr, fns, reducer = addToArray, initial = []) =>
arr.reduce(compose(...fns)(reducer), initial);The alternative solution, without transducers, involved a straightforward loop working with an array (fnList) of the operations to apply, identifying each either as a mapping ("M") or a filtering ("F"). Again, for full details, I recommend you check the previous article.
const singlePassMoreGeneral = (
someArray,
fnList,
reduceAccumFn = (accum, value) => {
accum.push(value);
return accum;
},
initialAccum = []
) => {
let result = initialAccum;
someArray.forEach((value) => {
if (
fnList.every(([type, fn]) => {
if (type === "M") {
value = fn(value);
return true;
} else {
return fn(value);
}
})
) {
result = reduceAccumFn(result, value);
}
});
return result;
};From the code, it seems there isn’t much we can do to optimize the transducer solution - it’s a single line, after all! However, we can likely enhance the second solution, so let’s first think about measuring their performance.
Measuring Performance
How do we measure performance? We need to get actual, accurate timings. Also, we cannot make do with a single measure because the performance of the code depends to a great degree on the functions and data we’ll work with.
In a previous article on higher order functions we saw a method to transform any function into a new one that reports the time it needs to perform its work. However, that won’t be precisely what we need. We’ll have to run several tests with random data to get valid measurements, so we don’t care for a specific run; we need to accumulate times for all runs.
The more common way to measure times is using the Performance interface, which can be used both on the front and back end. If you want to see an example of its usage, that’s exactly what we worked with when we wrote a timing higher-order function, as mentioned above.
For variety, I decided to go with another solution: Node’s process.hrtime() method. This method works similarly to performance.now() but returns a BigInt numeric value. The precision is greater: instead of milliseconds, we now get nanoseconds. OK, the question is obvious: do we need this level of precision? The answer is, sadly, not - but I did want to work with BigInt values, which I hadn’t used before, so I went ahead anyway!
Timing code is simplicity itself: you just get the value of process.hrtime.bigint() before and after running the code, and the difference between both values is the required time. We now know how we’ll measure times, so let’s move to planning the tests themselves.
Planning our tests
It’s fairly obvious that we cannot test our functions with all the possible arrays, plus all possible combinations of filtering, mapping, and reducing functions. Let’s just stay with the functions we used in both previous articles; a sample usage is below.
const testOdd = (x) => x % 2 === 1;
const duplicate = (x) => x + x;
const testUnderFifty = (x) => x < 50;
const addThree = (x) => x + 3;
const myArray = [22, 9, 60, 24, 11, 63];
const newArray = myArray
.filter(testOdd)
.map(duplicate)
.filter(testUnderFifty)
.map(addThree);
console.log(newArray); // [21,25]We will work with random arrays, with TEST_SIZE entries between 0 and 100. (I’m using a const so I can run differently sized tests by just changing its value.) In addition, we’ll run TRIALS runs so we get a variety of results; we’ll take the total time for all runs as our final measurement.
Finally, for variety, instead of using the testUnderFifty function, I modified it a bit so a random limit would be used instead of 50. Our basic code will be akin to the following, in which I am comparing the transducer version with the non-transducer one:
// generate random numbers
const random_0_100 = () => Math.floor(Math.random() * 100);
// set limit for filtering
let LIMIT_FOR_TEST = 0;
const testUnderLimit = (x) => x < LIMIT_FOR_TEST;
// one accumulator for each function to be tested
let accum1st = 0n;
let accum2nd = 0n;
.
.
.
for (let i = 0; i < TRIALS; i++) {
const myArray = [];
for (let i = 0; i < TEST_SIZE; i++) {
myArray[i] = random_0_100();
}
LIMIT_FOR_TEST = random_0_100() / 3;
start = process.hrtime.bigint();
const result1st = transduce2(myArray, [
testOddR,
duplicateR,
testUnderLimitR,
addThreeR,
]);
accum1st += process.hrtime.bigint() - start;
start = process.hrtime.bigint();
const result2nd = singlePassMoreGeneral(myArray, [
applyFilter(testOdd),
applyMap(duplicate),
applyFilter(testUnderLimit),
applyMap(addThree),
]);
accum2nd += process.hrtime.bigint() - start;
.
.
.
}
// report the values of accum1, accum2, etc.We will be doing TRIALS runs to try to minimize the effects of randomness and get better results. We will be working with large arrays because, in reality, for small arrays, both solutions require very short times, and optimization won’t have much effect. I decided to go with the following:
const TRIALS = 100;
const TEST_SIZE = 10_000_000;As to the tests, for each trial we initialize the array with TEST_SIZE random values between 0 and 100, we set a LIMIT_FOR_TEST that will be used by one of our filtering functions, and then we run different versions of our code, measuring the time that was required, and adding it to the corresponding total. When all trials are done, we simply report all the totals for further analysis.
As an extra check to be sure all implementations were correct, I also compared their results to be sure they matched. If an implementation had been buggy, I would have known that immediately. For example, after the 2nd calculation, I added:
console.assert(
JSON.stringify(result1st) === JSON.stringify(result2nd),
"test2nd"
);So, now we know how we’ll proceed with tests. Let’s start getting some results!
A first run
The first experiment compared our transducer version with the singlePassMoreGeneral (for brevity, SPMG) transducer-less version, and the results were terrible! Five complete trials consistently showed that the simpler version was about 35%-40% slower than the transducer one, a noticeable difference. (By the way, I created all charts using Canva.)
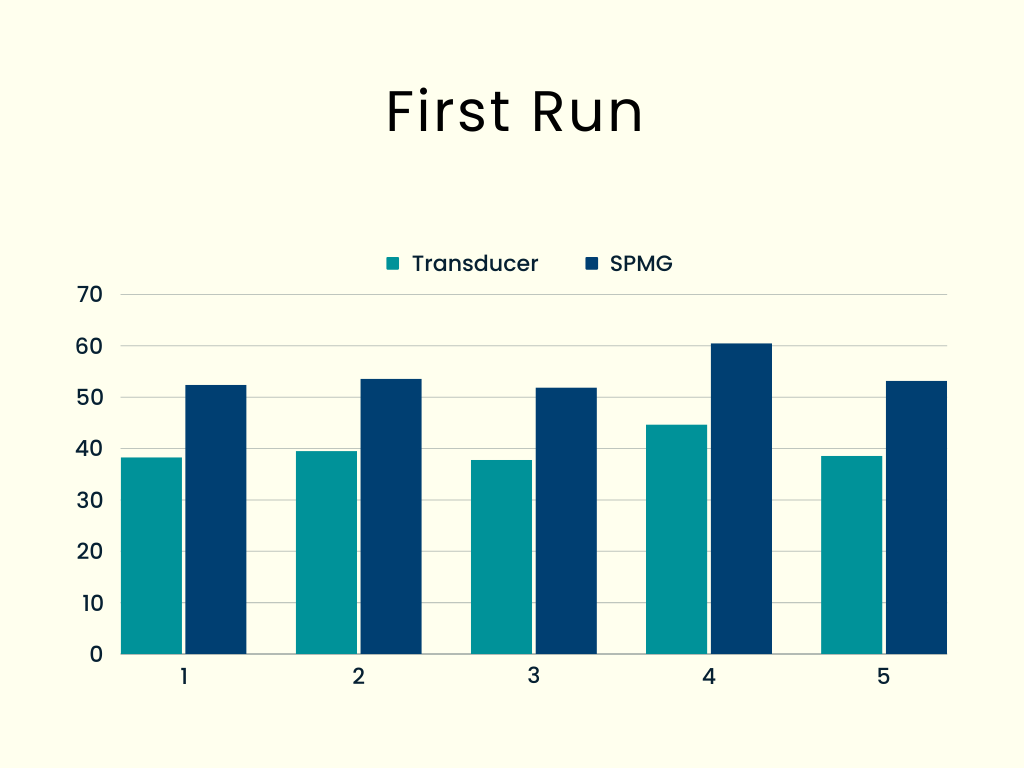 We must try to optimize the “no-transducer” version; let’s see how.
We must try to optimize the “no-transducer” version; let’s see how.
A second run: avoiding ifs
I created a third solution by avoiding the if statements. In each pass of the every() call, I had an if that I used to either update value or flag. I thought I could apply a transformation to the mapping and filtering functions:
- if I was doing a mapping, I’d update the first value and return a true for the second value, used to keep looping
- if I was doing a filtering, I’d keep the first value (no mapping done), and I would use the function to return true or false
const applyMap3 = (fn) => (value) => [fn(value), true];
const applyFilter3 = (fn) => (value) => [value, fn(value)];By applying this technique, there are no more if lines in the code; we can update both value and flag simultaneously.
const singlePassMoreGeneralNoIf = (
someArray,
fnList,
reduceAccumFn = (accum, value) => {
accum.push(value);
return accum;
},
initialAccum = []
) => {
let result = initialAccum;
someArray.forEach((value) => {
let flag = true;
if (
fnList.every((fn) => {
[value, flag] = fn(value);
return flag;
})
) {
result = reduceAccumFn(result, value);
}
});
return result;
};This meant I could add a new comparison.
start = process.hrtime.bigint();
const result3rd = singlePassMoreGeneralNoIf(myArray, [
applyFilter3(testOdd),
applyMap3(duplicate),
applyFilter3(testUnderLimit),
applyMap3(addThree),
]);
accum3rd += process.hrtime.bigint() - start;The results were, alas, awful!
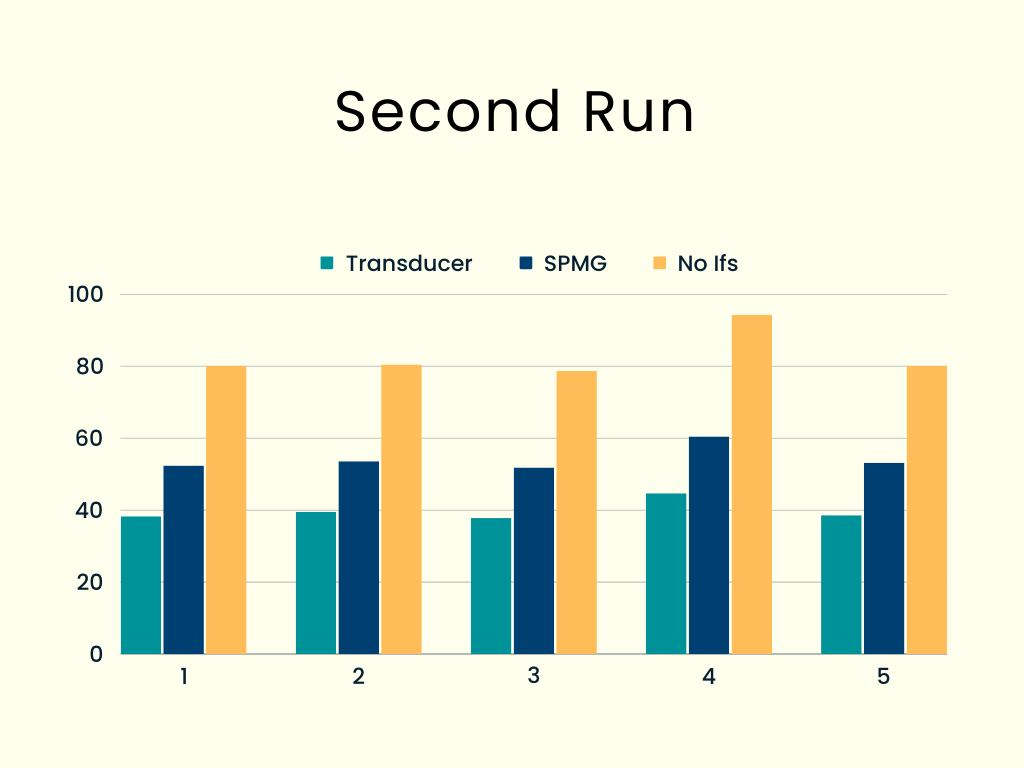 Using this technique doubled the times. It may have been a very functional idea, but its performance didn’t pay off. Let’s try something else!
Using this technique doubled the times. It may have been a very functional idea, but its performance didn’t pay off. Let’s try something else!
A third run: using loops
OK, given that most of the time involves loops, I decided to try another tack. If you google a bit, several articles mention that the faster loops are the basic for() kind. Thus, I modified the non-transducer original code to avoid both forEach() and every().
const singlePassMoreGeneralWithLoops = (
someArray,
fnList,
reduceAccumFn = (accum, value) => {
accum.push(value);
return accum;
},
initialAccum = []
) => {
let result = initialAccum;
loop: for (let i = 0; i < someArray.length; i++) {
let value = someArray[i];
for (let j = 0; j < fnList.length; j++) {
if (fnList[j][0] === "M") {
value = fnList[j][1](value);
} else if (!fnList[j][1](value)) {
continue loop;
}
}
result = reduceAccumFn(result, value);
}
return result;
};How to break out of the inner loop? The every() method stops when its condition is unmet. To do the same, I had to use a continue statement to return to the outer loop’s top.
The test for this function was the same as for the original non-transducer one, and the results were excellent indeed; times were around 20% less than the transducer ones!
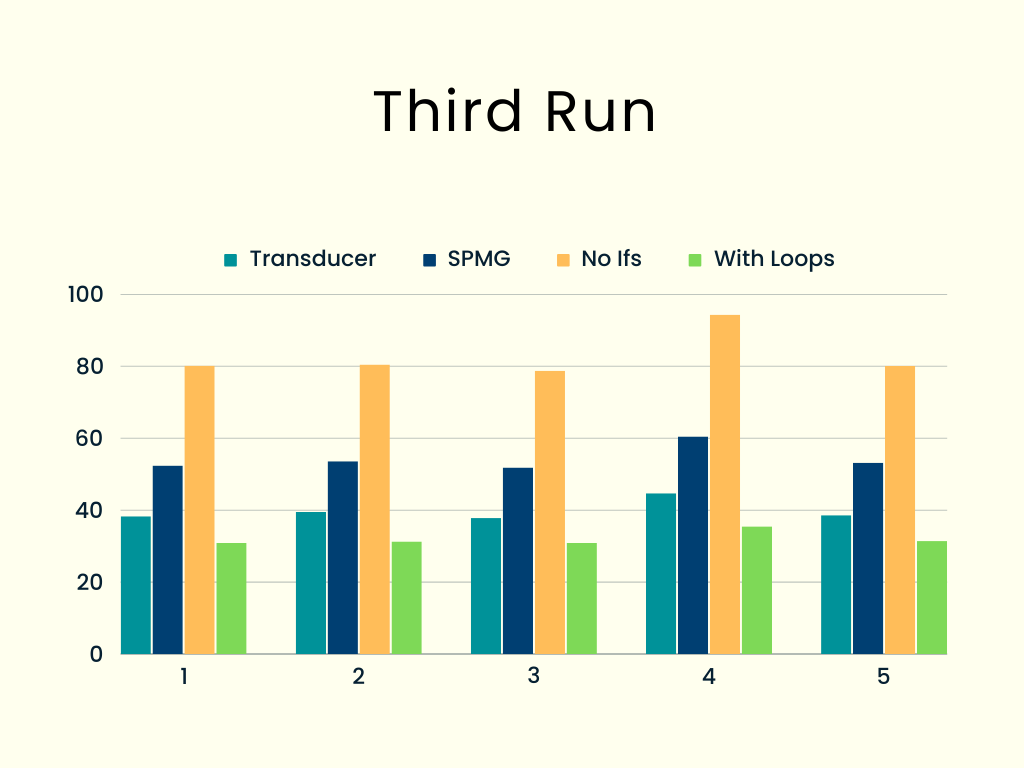 This idea did pan out; going with simple loops is decidedly better. How can we get even more speed?
This idea did pan out; going with simple loops is decidedly better. How can we get even more speed?
A fourth run: using loops and variables
A common optimization is storing array values in variables so you can access them faster. If you check the code in the previous section, we could use a variable to store fnList[j] and avoid one indexing access.
We can also avoid accessing the .length property; we can use a pair of values to store the lengths of the someArray and fnList arrays for this.
Finally, to avoid having JavaScript create variables many times, we can also define i, j, etc., before all looping, so there will be no new variables anywhere. The modified code is as follows:
const singlePassMoreGeneralWithLoopsAndManyVars = (
someArray,
fnList,
reduceAccumFn = (accum, value) => {
accum.push(value);
return accum;
},
initialAccum = []
) => {
const someArrayLength = someArray.length;
const fnListLength = fnList.length;
let i;
let j;
let value;
let fnListJ;
let result = initialAccum;
loop: for (i = 0; i < someArrayLength; i++) {
value = someArray[i];
for (j = 0; j < fnListLength; j++) {
fnListJ = fnList[j];
if (fnListJ[0] === "M") {
value = fnListJ[1](value);
} else if (!fnListJ[1](value)) {
continue loop;
}
}
result = reduceAccumFn(result, value);
}
return result;
};The code has grown in size, indeed! However, the results are nothing to write home about; performance is essentially the same, sometimes a little bit above and sometimes a little bit below, but with no noticeable difference.
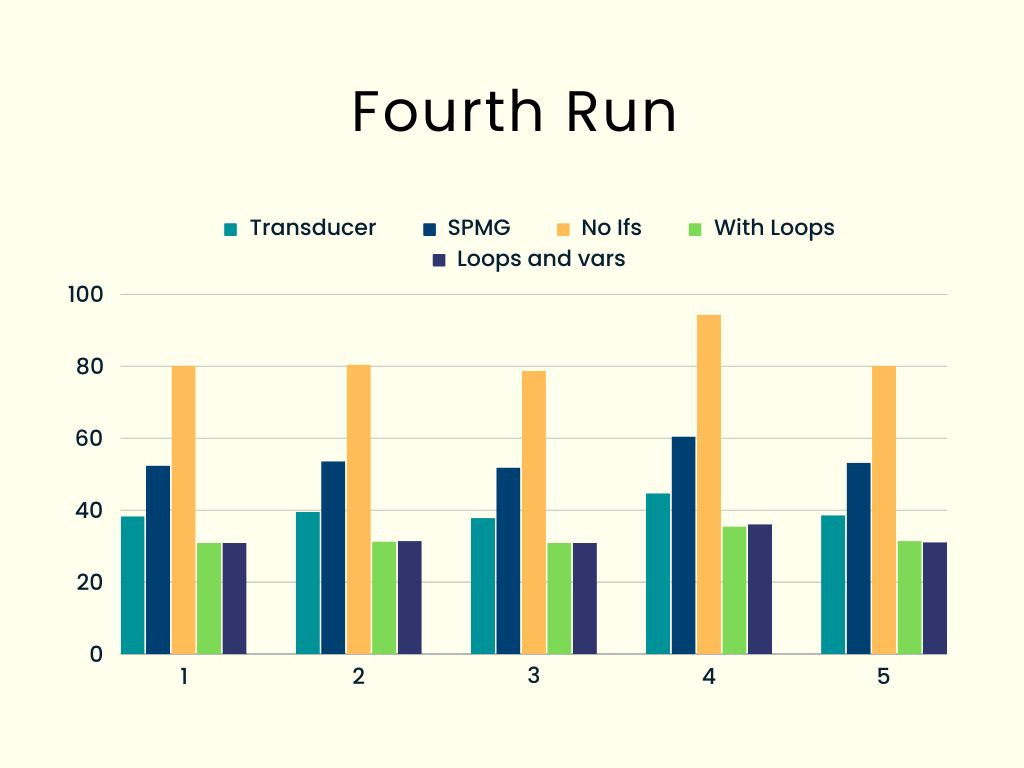 So, our code with common loops is still best. Let’s try a final idea!
So, our code with common loops is still best. Let’s try a final idea!
A fifth run: using objects or arrays
I still liked the functional idea I had tried in the “avoiding ifs” section, and wondered how it would work in the loop-based code.
const singlePassMoreGeneralWithArray = (
someArray,
fnList,
reduceAccumFn = (accum, value) => {
accum.push(value);
return accum;
},
initialAccum = []
) => {
let result = initialAccum;
let value;
let flag;
loop: for (let i = 0; i < someArray.length; i++) {
value = someArray[i];
for (let j = 0; j < fnList.length; j++) {
[value, flag] = fnList[j](value);
if (!flag) continue loop;
}
result = reduceAccumFn(result, value);
}
return result;
};We are working the same way; our fnList functions now return an updated value or flag, but with no if statements. How did it work out?
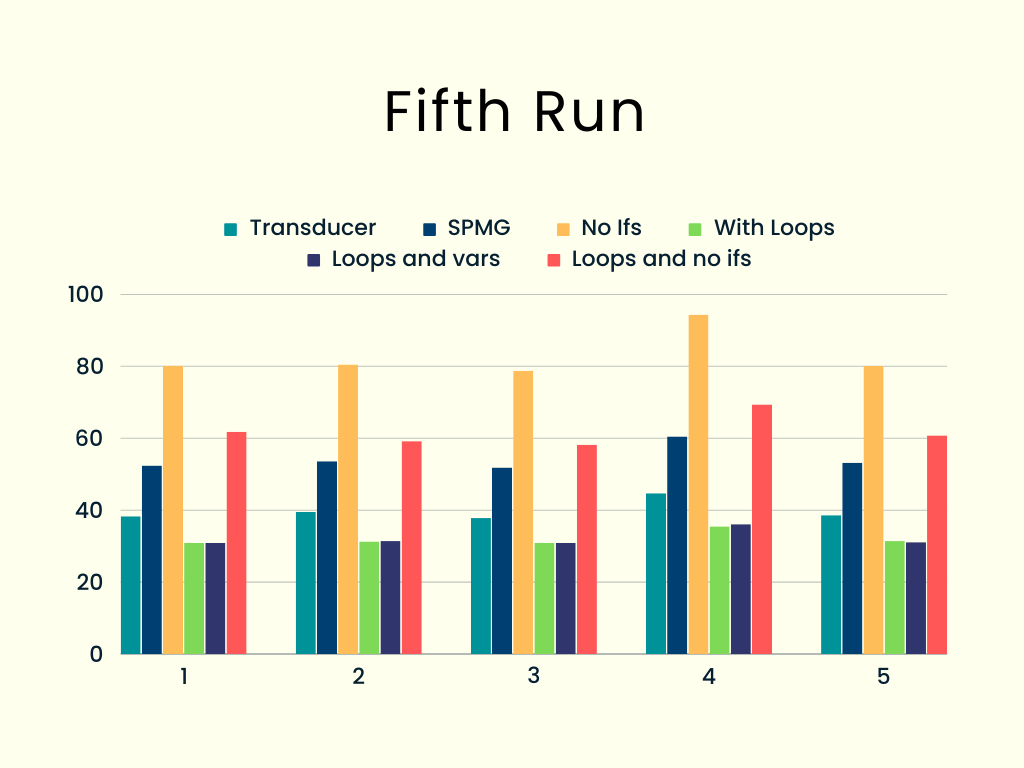
Still no good, unfortunately! I also tried a modified version, returning an object instead of an array, but other than that, it was essentially the same, and it was better (I didn’t expect that) but still much worse than the version with just loops.
Conclusion
In the previous two articles, we examined an optimization problem and found two distinct solutions: one very functionally oriented and another more “common-styled,” using simpler tools. In this article, we analyzed their performances and found that the second solution was noticeably slower than the first, functional one. We planned how to test times, ran tests, and then applied several changes to the second function to find better performance. Some of the changes were much worse, but we managed to get a better, faster solution. The main takeaways from this article, apart from the optimization’s success, are how we wrote the (random) tests, how we measured times, and how we made our code evolve into a better function. You can now apply the same procedures to your work; good luck!
Understand every bug
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — the open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
